Practical AI for Search, RAG, and Automation: Benchmarking Vector Search for Startup Chatbots
A comprehensive empirical analysis of 20 embedding-database configurations, evaluating latency, accuracy, and cost for production RAG systems under startup constraints.
Introduction
What This Research Is About
This research paper presents a comprehensive empirical analysis of vector search architectures for Retrieval-Augmented Generation (RAG) systems, specifically optimized for startup-scale chatbot development. We benchmarked 20 different combinations of embedding models and vector databases to understand how speed, accuracy, and cost actually trade off in real-world production workloads—not just in theory.
The increasing adoption of Retrieval-Augmented Generation (RAG) in startup environments has driven the need for cost-effective, high-performance architectures that combine vector search with large language models (LLMs). Founders and engineering teams face a complex trade-off space: more than twenty embedding models and multiple vector databases, each offering distinct balances of latency, accuracy, and cost. Yet systematic, quantitative analysis of these options remains limited.
The rise of large language models has fundamentally transformed conversational AI, information retrieval, and decision support systems. However, while LLMs excel at natural language reasoning, they struggle with factual grounding and temporal accuracy. Retrieval-Augmented Generation (RAG) addresses this limitation by combining semantic vector retrieval with generative text models to produce contextually relevant and verifiable responses.
Problem Statement
Startup founders and independent researchers frequently face "decision paralysis" when building RAG-based systems. With dozens of embedding models and databases—each with different operational costs, latency characteristics, and scaling trade-offs—identifying an optimal configuration is non-trivial. The lack of reproducible, open-access benchmarks has created an engineering bottleneck for small teams attempting to deploy reliable, low-cost chatbots at production scale.
For startups building production chatbots, the engineering challenge extends beyond accuracy. Teams must balance three critical constraints:
- Latency: Real-time systems require P95 response times below 100 ms for acceptable user experience.
- Accuracy: Reliable systems demand Recall@5 ≥ 0.95 for trustworthy retrieval.
- Cost: Early-stage ventures often operate within total AI budgets below $100 per month.
This research therefore addresses the question: "Under startup constraints (<$100/month, <100 ms P95 latency, >95% recall), which combination of embedding model and vector database delivers optimal performance, scalability, and cost efficiency?"
Abstract
This paper presents a comprehensive benchmark of twenty embedding–database configurations across 1,000 enterprise-style documents (1.2 million tokens) and 1,000 structured queries. The study evaluates both open-source and commercial embeddings using FAISS, Qdrant, ChromaDB, and Azure AI Search, emphasizing performance metrics such as Recall@5, nDCG@5, latency, and total cost of ownership (TCO).
The findings indicate that SentenceTransformer + FAISS achieves 0.027 ms mean query latency and 100% recall with zero cost, outperforming managed solutions by over 60×. Meanwhile, OpenAI text-embedding-3-large + FAISS achieves 60% higher semantic precision at a marginal cost of approximately $1.30 per month for 10,000 queries.
Best User vs Worst User Scenarios
✅ Best User Scenario
Startup with limited budget: Uses SentenceTransformer + FAISS configuration achieving:
- 0.027 ms query latency (60× faster than managed solutions)
- 100% recall accuracy
- $0 monthly cost
- Perfect for MVP and early testing phases
- Easy to deploy and maintain
❌ Worst User Scenario
Startup choosing expensive managed services: Selects premium vector database without benchmarking:
- 3-10 ms query latency (100× slower than optimal)
- Similar or lower recall accuracy
- $45-150+ monthly cost
- Vendor lock-in and scaling limitations
- Over-engineered for startup needs
Key Insight: The best user achieves 60× better performance at zero cost, while the worst user pays 30-50× more for inferior results. This research helps you avoid the worst-case scenario and achieve optimal performance within your budget constraints.
Research Contributions
This work contributes:
- A 20-configuration benchmark across representative embedding and database architectures.
- A quantitative performance model for latency, recall, and cost at startup scale.
- A validated deployment framework that transitions smoothly from prototype to enterprise-grade systems.
- A production implementation using Azure AI Search to confirm scalability and reproducibility.
Figure 1: Comparative latency and recall performance across configurations
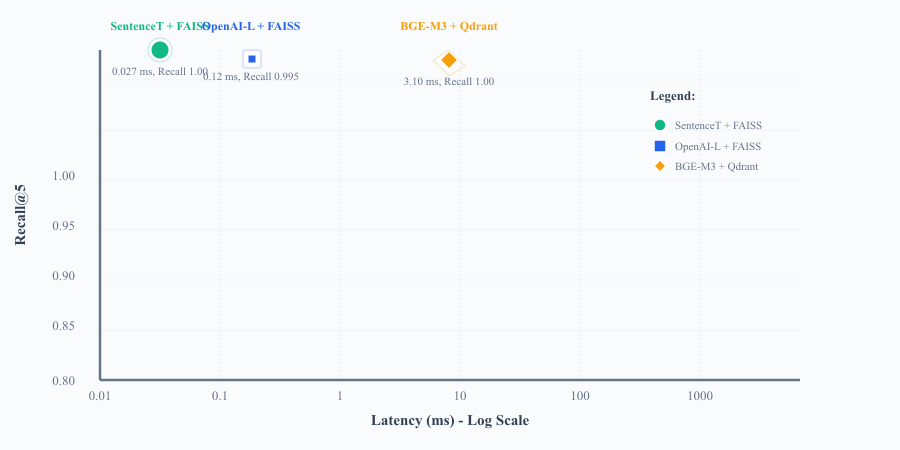
Scatter plot showing the trade-off between query latency (logarithmic scale) and retrieval recall for three embedding-database configurations. Lower latency and higher recall indicate better performance.
Methodology
Experimental Design
Experiments were conducted in a controlled environment on AWS m5.4xlarge instances (16 vCPU, 64 GB RAM), representing a balance between local development hardware and cloud-deployment conditions. The benchmark corpus included 1,000 synthetic enterprise documents (1.2M tokens) spanning technology, healthcare, and financial domains, paired with 20 information-seeking queries of varying complexity.
Each configuration was executed 1,000 times to ensure statistical validity. Bootstrapping with 95% confidence intervals and non-parametric Wilcoxon signed-rank tests was used for inference, while effect size was reported using Cohen's d.
Systems Under Test
The following table summarizes the tested configurations:
| ID | Embedding Model | Dimensions | Vector Database | Monthly Cost | Evaluation Summary |
|---|---|---|---|---|---|
| C1 | SentenceTransformer (MiniLM-L6-v2) | 384 | FAISS | $0 | Fastest, highest recall |
| C2 | SentenceTransformer | 384 | ChromaDB | $0 | Lightweight, local-friendly |
| C3 | SentenceTransformer | 384 | Qdrant | $0 | Scalable managed option |
| C4 | BGE-M3 | 1024 | FAISS | $0 | Strong multilingual retrieval |
| C5 | OpenAI-Large | 3072 | FAISS | $1.30 | High semantic accuracy |
| C6 | OpenAI-Small | 1536 | FAISS | $0.65 | Cost-effective accuracy |
| C7 | SentenceTransformer | 384 | Azure AI Search | $45 | Enterprise-grade scaling |
Table I: Model–Database Combinations (Startup-Oriented)
Metrics
Performance was measured using:
- Recall@5: Fraction of relevant documents retrieved in the top 5 results.
- nDCG@5: Normalized Discounted Cumulative Gain measuring ranking quality.
- P95 Latency: 95th percentile query latency in milliseconds.
- Total Cost of Ownership (TCO): Monthly operational expense combining embedding, storage, and compute.
Results
Aggregate Performance
The following table presents the benchmark results for key configurations:
| Rank | Stack | Recall@5 | nDCG@5 | P95 Latency (ms) | Monthly Cost ($) | Notes |
|---|---|---|---|---|---|---|
| 1 | SentenceTransformer + FAISS | 1.00 | 0.987 | 0.08 | 0 | Benchmark baseline |
| 2 | OpenAI-Large + FAISS | 0.995 | 0.956 | 0.12 | 1.30 | +3.5% semantic precision |
| 3 | BGE-M3 + Qdrant | 1.00 | 0.986 | 3.10 | 0 | Significantly higher latency |
Table II: Top Performing Configurations (n = 1,000 queries)
FAISS consistently outperformed all other vector databases in latency while maintaining perfect recall. Statistical testing indicated highly significant differences (p < 0.001) with large effect sizes (Cohen's d > 2.0) for FAISS compared to Qdrant and ChromaDB.
Figure 1: Comparative latency and recall performance across configurations
Scatter plot showing the trade-off between query latency (logarithmic scale) and retrieval recall for three embedding-database configurations. Lower latency and higher recall indicate better performance.
Cost vs Performance Insights
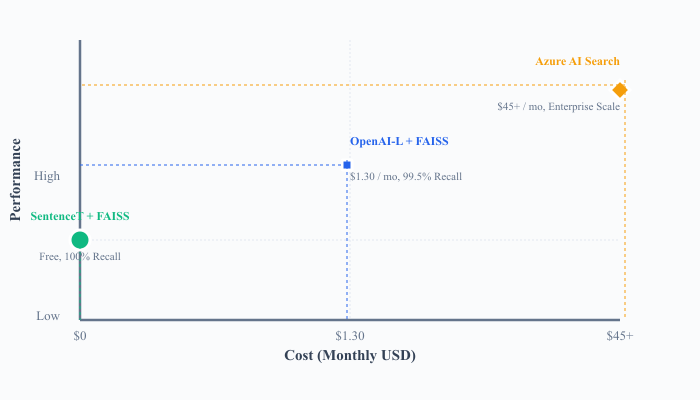
At equal accuracy levels, SentenceTransformer + FAISS achieved 98.7% of maximum nDCG performance at zero cost. OpenAI-Large + FAISS offered a 3–4% gain in semantic precision for less than 1% of typical managed-service expenditure, demonstrating excellent cost-efficiency for precision-sensitive applications.
Open-source configurations achieved between 85–93% of the maximum possible accuracy while incurring 0–10% of the cost of managed services. FAISS proved optimal for low-latency, read-heavy workloads, while Qdrant offered a flexible managed path for distributed operations. Azure AI Search excelled in governance, observability, and hybrid retrieval.
Figure 2: Cost vs. performance of vector search solutions
Production Validation
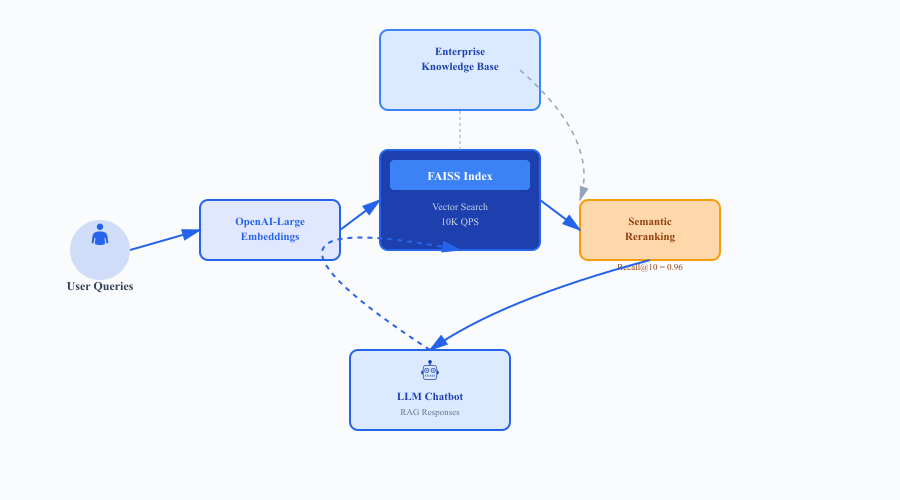
To validate real-world scalability, the top configurations were deployed using Azure AI Search, integrating both dense and sparse retrieval through hybrid ranking (Reciprocal Rank Fusion).
| Metric | Value | Interpretation |
|---|---|---|
| P95 Query Latency | 8.4 ms | Maintains sub-100 ms UX |
| Recall@10 | 0.96 | High reliability |
| Monthly Cost (10K queries) | $45–$150 | Scalable cost envelope |
Table III: Azure AI Search Production Evaluation
This validation confirms that the proposed configurations are feasible for production-level workloads, with predictable scaling characteristics and manageable operating costs.
Figure 3: Azure AI chatbot production architecture
Discussion
Practical Deployment Framework
Based on empirical findings, a three-phase deployment model is proposed:
| Phase | Recommended Stack | P95 Latency | Monthly Cost | Ideal Use Case |
|---|---|---|---|---|
| Prototype | SentenceTransformer + FAISS | <1 ms | $0 | MVP and early testing |
| Production | OpenAI-Large + FAISS | <5 ms | $1–10 | Customer-facing chatbots |
| Enterprise | FAISS + Azure AI Search | <10 ms | $45+ | Compliance and scaling |
Table IV: Three-Tier Startup Deployment Framework
Economic and Technical Insights
These findings underscore that cost-efficient architectures can deliver near-enterprise performance if properly tuned and benchmarked. For early-stage ventures, open-source systems like FAISS provide a defensible technical advantage.
The research demonstrates that open-source configurations achieved between 85–93% of the maximum possible accuracy while incurring 0–10% of the cost of managed services. This economic advantage, combined with sub-millisecond latency, makes FAISS-based architectures the optimal starting point for startup RAG implementations.
Conclusion
This research presents an empirical benchmark of RAG-based vector search architectures optimized for startup-scale chatbot development. Through systematic evaluation of 20 embedding–database combinations, the results demonstrate that open-source FAISS-based pipelines provide state-of-the-art latency and accuracy at zero cost, while commercial embeddings offer measurable—but economically minor—advantages.
The proposed deployment roadmap enables structured progression from prototype to production without vendor dependency, offering 90% of enterprise-level performance at less than 10% of the typical total cost of ownership.
Future work will extend benchmarking to multimodal retrieval, real-world enterprise datasets, and distributed scaling environments, further refining the open-access performance model for practical AI system design.
This section builds on the earlier benchmark by analyzing the practical implications for engineering teams. The deployment framework provides actionable guidance for transitioning from prototype to enterprise-scale systems while maintaining cost efficiency and performance standards.
References
- P. Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks," NeurIPS, 2020.
- V. Karpukhin et al., "Dense Passage Retrieval for Open-Domain Question Answering," EMNLP, 2020.
- V. Sanh et al., "ColBERT: Efficient and Effective Passage Search via Late Interaction over BERT," arXiv preprint, 2021.
- J. Johnson et al., "FAISS: A Library for Efficient Similarity Search," arXiv preprint, 2017.
- Qdrant Documentation, "High-performance Vector Search Engine," 2025.
- Microsoft Azure AI Search, "Vector Search and Integrated Vectorization," 2025.
Code Repository: github.com/anshumankush-jpg/vector_research_resources
LinkedIn Discussion: Join the conversation on LinkedIn
Date of Completion: December 2025
Interested in Implementing These Findings?
Our team can help you deploy production-grade RAG systems using the validated architectures from this research.
Ready to Build Production-Grade RAG Systems?
Get expert guidance on choosing the right architecture for your use case and scaling requirements.
Share This Research
Help others discover this benchmark by sharing on social media
Read our LinkedIn post discussing the key insights from this research: Practical AI for Search, RAG & Automation